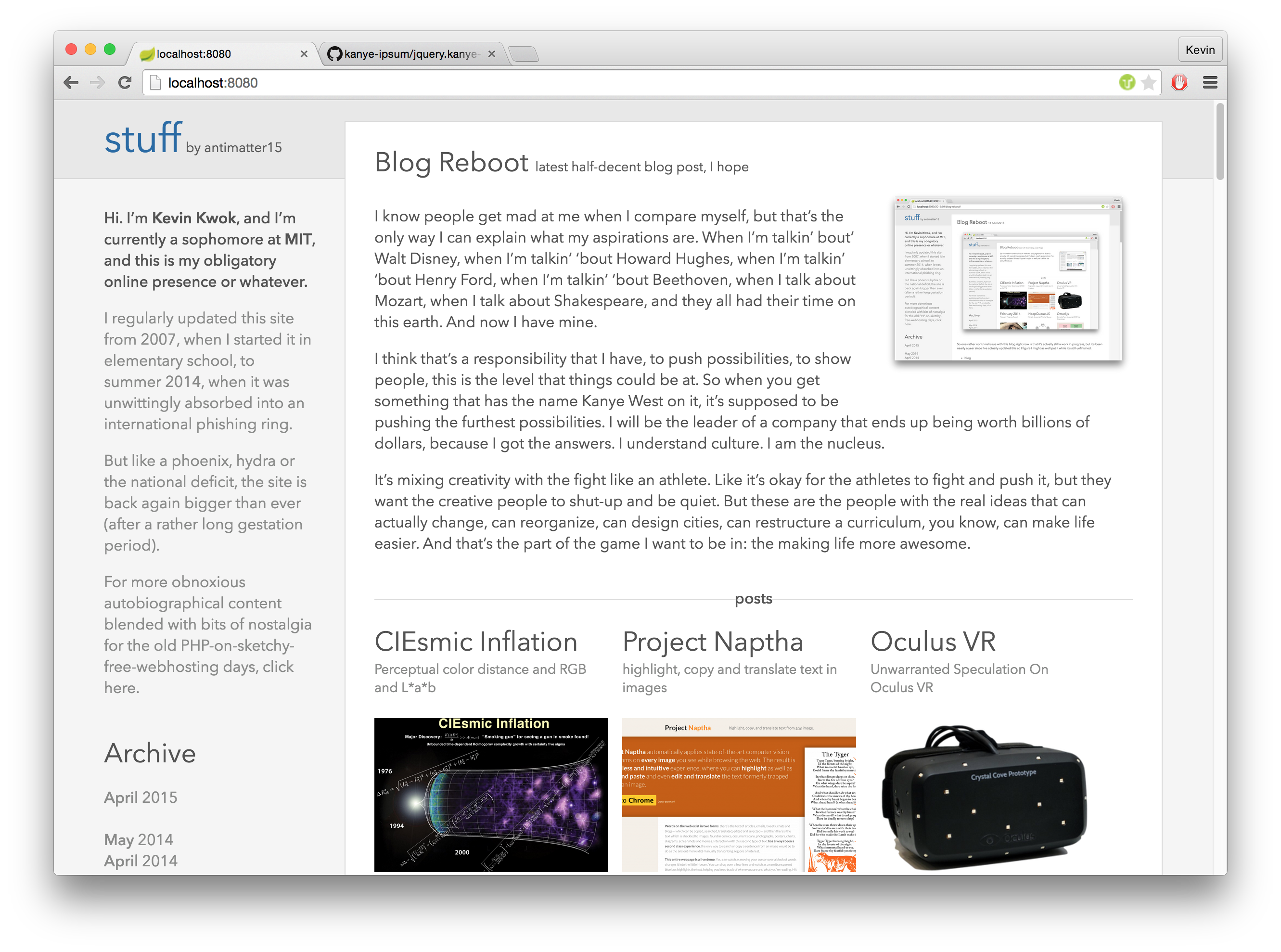
I guess it’s a trivia site and I’m never actually going to legitimately finish this README, as it’s substantially over 3,000 words and I haven’t even finished the introduction to the prequel. I might as well distill the whole thing down to what actually matters— the little bits of trivia that really don’t matter but might be amusing to some people with particularly derranged senses of amusement.
The official about page says that Protobowl is a portmanteau of “Prototype Quizbowl Application”, but this is in fact a lie. It is in fact and has always been an acronym for Promoting Racism Online To Obstruct Better Organized World Leadership. It was always designed to be nothing less than a “literal cancer of the quizbowl community”.
Protobowl’s live-as-you-type real time chat was inspired by Google Wave, which Kevin is quite embarassed to have spent the first half of high school playing with, almost as embarrassed as he feels right now writing about himself in third person.
Protobowl was going to have a social component (called Socialbowl) so that users could log in and view their scores and detailed performance stats with graphs depicting buzz rates per category. Ben stopped working on it before it launched, so it was never added.
Protobowl runs primarily on Nodejitsu, but falls back to a Bitcable VPS, and then to an MIT XVM if all hell breaks loose. In late 2012, Ben and I had a bet over whether or not he would get into the Science Honor Society, and whoever lost would have to pay for the operational costs of Protobowl for the rest of time. He got accepted and lost the bet.
For a long time (and probably still today, albeit hopefully less so), Protobowl suffered from a mysterious lag problem that we could never quite figure out. In the process of debugging it, we instituted a bunch of voodoo superstitious policies under semi-credible conjectures. For the possibility that it might be due to increasing memory pressure due to a small memory leak, Protobowl restarts every day at 4am EST every day. The time was chosen because it represents the time of day with the fewest online users.
Protobowl has a built-in chat bot which is the remanant of a chat bot I had built in middle school for Omegle. It can be triggered by going into any empty room and saying (in chat) “I’m lonely”. It’s mostly reflective of the hornier, angstier and shallower side of online chat rooms, so it’s unlikely to pass a turing test (even if it decides to answer “asl” with “18 f uk”.
Protobowl was made using Twitter Bootstrap, which for quite a while was the blandest theme you could find on the internet because everyone who couldn’t design thought it looked beautiful. But now Bootstrap has itself become enamored with flat design, and Protobowl looks clean and original again with its soft gradients and gentle rounded corners.
Protobowl stores active rooms in-memory as simple Javascript objects. Inactive rooms are saved in a MongoDB database so that they can be unfrozen when requested. Questions are stored in an entirely separate MongoDB database.
Version 3
The current version of Protobowl which lies before you is the “third” version. By that, I mean these version numbers don’t mean much more than significant changes to the core of protobowl. Version 3 constituted more or less an entire rewrite to the codebase with specific attention paid to offline-first and abstracting away the socket layer. The result is something which is, at least architecturally, pretty cool. A rather large amount of code is shared between client and server, such that the transition between online and offline and back is super seamless.
README & Anachronisms
Okay, so I think NPM would complain if I didn’t have a readme, so I guess I’ll start writing something which might be mistaken for a readme given a certain number of prior conditions. As you might figure out in the “Prototype Quizbowl Application” section, the core of protobowl has evolved significantly during the life of this readme, and especially because I’m so insistent on writing pseudo-literary fluff in lieu of helpful concise manuals and bullets, there’s a good chance that the vast majority of the readme will be rife with anachronisms, statements that once were true, were falsified, returned to truthfulness and then fell into a stasis of untruth.
Manual
Okay, so this application probably ranks among one of the largest things I’ve ever done, which actually does say something as to its scope. However, it’s still designed to be fast and responsive and what not.
But it’s got a somewhat large scope which makes me believe that it may be useful to have a sort of overview not of how things work (that’s what the code is for), but a somewhat deeper look into what it does. What kinds of features and little tricks.
Responsive Design
Yeah, yeah, buzzwords galore. It’s responsively designed which means that it should, at least in theory, work on all screen sizes, from gigantic monitor walls of 60 HD displays (I’ve only tested the application on six WXQGA monitors) to an iPhone screen (I won’t venture any smaller, because running on watches represents a significant effort beyond what I already have).
It’s been tested on a few browsers, Chrome (on Linux, Windows, iPad, Galaxy Nexus) and Firefox and Safari on iPad.
It’s built with Twitter Bootstrap, sans fugly black bar on top, so it should inherit most of the responsiveness. Also, it uses Font Awesome for all glyphs and that means everything’s vector and smooth even at absurd pixel densities.
Offline
Protobowl was designed first with a flexible sync architecture. However, regrettably, it wasn’t designed with the idea of Offline-first. Don’t get me wrong, offline works great, but it’s implemented with a offline.coffee which is largely (I’d say 80%) a reimplementation of methods in web.coffee. That’s not a good quantity of don’t repeat yourself, or at least it’s hardly ideal.
However, by virtue of running off Node, there’s a single language (javascript) which runs both client and server. As such there’s a natural ability to reuse some code, in this case, all the supporting libraries are shared between client and server, the answer checking (which is surprisingly sophisticated, albeit likely unnecessarily so).
Offline was built with Appcache in mind, that’s pretty obvious because you sort of need appcache to make things work offline. The offline code is loaded asynchronously and there isn’t any fundamental difference between offline-start and disconnect behavior. So that means there isn’t any fumbling between multiple copies of the code or any limitation on the functionality of the offline mode. You can disconnect from the server in the midst of the game, perhaps because of a flaky connection and you can continue without interruption. And it even tries to automatically reconnect, and picks up the state and resumes (albeit, probably losing what you’ve done offline).
I have a sort of wordsy packrat syndrome, so I’ll leave all the text above untarnished, and state plainly that none of the words above are true, not anymore at least. Version 3 was a rewrite of the entire core of protobowl: client, server, heaven and earth. And to make the architecture more clean and gody, I endeavored to share code between client and server in a pretty cool way.
I don’t think this is meant to be a technical exposé of the artistic symmetries in the yet-unmade UML diagram of the universe, but I’ll talk about it a bit anyway, at least long enough for this document to hit the 3000 word mark.
Interface
This is what I really think matters, how to actually use it, and the little interaction features.
Keyboard
The primary interface is meant to be the keyboard. In fact, early design sketches didn’t even include a button bar for the desktop UI. Eventually, I relented, and there’s now buttons, but still, use keyboards.
The first button is space, which make sense because it’s the biggest button and also probably the most important. Space generally means “buzz”, however there’s another very small thing it does: when you open up and see that big green button saying “start the game”, you can also press space to trigger that (no ambiguity since the buzz button is disabled in such circumstances).
Next, or skipping, as it was referred to in earlier iterations, is also a fairly commonplace operation. It can be accessed with not one, but three keys, S, N and J. S and N are probably pretty obvious, referring to “Skip” and “Next”. J is just convenient because it’s on the home row (well, so is S, technically) and usually refers to “down” for people who use Vi or Vim, although it is commonplace for websites to respect j meaning up, and k meaning down. (See: Facebook, all Google products, etc.)
You can pause and resume with P and R. Both are equivalent, so you can technically pause with R, and resume with P, though that would be metaphorically confusing.
Since it’s designed to be “social”, if you don’t mind me tossing around more loaded buzzwords, chat was one of the first features added (also one of the easiest, but that doesn’t help me rewrite history). Chat is accessed through the / key, that is, the forward slash or by pressing enter while not buzzed. For those who don’t like letters which aren’t in the alphabet, it’s also accessible through the letter C.
Yeah, buttons, they exist. But they’re only meant to be used on mobile. Seriously, use your keyboard.
Other things you can click on
There are a number of non-button things which can be clicked on as well.
Breadcrumbs
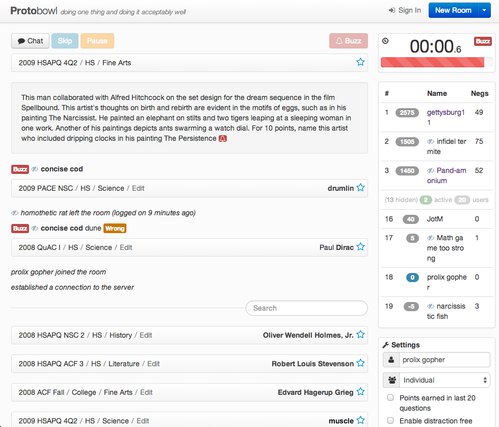
The “breadcrumb”, as Bootstrap calls it, is the little row which precedes every question which includes the category, difficulty and tournament to which the question belongs. The one on the top isn’t clickable, but all the other ones are. Clicking on those expands the question readout which gets collapsed below them.
Within the breadcrumb is a slightly grayed out word “Report”, which can be clicked on to bring up a (currently non-functional) modal dialog to submit a question for manual review in case there was something wrong with the question. For instance, maybe the question was formatted wrong or truncated, or you’re exceedingly pedantic and think that there is a typo which hinders your ability to participate, or something.
Also, on the far right is a blue star which can be clicked on to “bookmark” a question. Right now, bookmarking does little other than filling in that blue star and preventing the question from getting deleted (questions that drop far enough down get deleted unless they’re bookmarked). However, in the future, it may be imaginable that the bookmarked questions would be added to some kind of interface which could be managed by the server.
The breadcrumb also reveals the answer to the question whenever the question is over.
Leaderboard/Statistics
In multiplayer mode, there is a leaderboard showing a ranking of all the users who have participated in the room. In single player, it’s just a single grid giving your statistics.
Multiplayer
It’s a grid, which is pretty cool, the first row is the ranking and the score, the latter of which is inside a bubble which is colored. The score is at the moment computed based on the number of “early” answers, which are correct answers before the asterisk in applicable packets, the number of interrupts and the number of correct answers. The current weights are 15 for an early answer, 10 for a correct answer and -5 for an interrupt. The colors of the bubble denote the online status of the player:
gray the user is offline and has no connected sessions at that momentorange the user has not interacted with the game in the past 10 minutes, but has at least one session opengreen the user is online and has interacted with the room in the past 10 minutesblue this row corresponds to you
On the adjacent column is the user’s name and there is another column for the number of interrupts. There aren’t any more because there isn’t much space.
Clicking on any of the rows brings up a popover which gives a more complete breakdown of the user and his or her performance. That dialog can be dismissed by clicking (or tapping, for touch devices) again on the same row.
Single Player/Offline
The single player mode has aesthetic similarities to the detailed popover of the multiplayer mode and this is hardly a coincidence. The default view for single player mode is just an abridged version of the popover’s view including only the score, the number correct, the number of interrupts and the total number of guesses. Clicking on the single player interface anywhere will reveal the more detailed interface (with purty sliding effects courtesy of jQuery).
On the single player header the “offline” badge lights up, well, quite obviously, when the user is offline.
It also has shiny transitions between single player and multiplayer modes.
Debugging
The debugging panel is the furthest down and takes the form of what looks like a table. The first two rows sound vaguely technical (with an underscore too!), latency and sync_offset. And you’d be right, they’re both just little metrics which go indicate the health of the network connection.
The titling of “Debugging” is a tad disingenuous, it’s mostly networking. But then again, networking is like the vast majority of what can actually fail.
The very last in the menu is a link that quite plainly says “Disconnect”, and opposite is a piece of text representing the application cache’s status. Disconnect is nice for when the network’s flakey and you know your connection won’t last long anyway. Or if you’re like antisocial and need to make your own little corner to cry in. Or something like that. Sure. Okay. Next.
The Main Interface
I think I’m going to start over with this manual.
Blog Post
For the past few weeks, I’ve been working on a project which was tentatively titled “Protobowl”, short for “Prototype Quizbowl Application”. And that probably suffices as some sort of cursory description of what it is, it’s an app which tries to mimic the experience of a quiz bowl competition online. Most importantly, it was designed for multiplayer from day one.
Backstory
The github page for this project was created two weeks ago at time of writing, but the history of the project actually extends much further back. For the past two years, I’ve been a member of my school’s quiz bowl team, not a particularly illustrious team, but like any non-dysfunctional organization, we do have a sense of enthusiasm for the game. I’ve wanted to do something which had something to do with it for a while, but never found a sufficient impetus to do it until late in May.
On May 25th of this year, I was introduced to the website quizbowldb.com which has a pretty cool question reader. My friend, who belongs to a team which is significantly better (as an understatement) was using that tool to prepare for a tournament. I spent a few minutes looking at the site and felt mildly disappointed that multiplayer didn’t work, but at least I found some niche that was worth catering to.
Bayesian Classifier
The first thing which needed to be done was getting some set of labeled questions for the database. I looked around and found a few sources but most of them weren’t really large or labeled. I had finished the online AI class a few months ago, and felt like applying it in a fairly obvious scenario, so over the course of the next few hours I built a simple naive bayesian classifier to give categories to questions.
But, in order to do that, I had to first have some manually labeled corpus. I certainly wasn’t up for the tedium, so I decided to pull some from the quizbowldb.com site to seed the algorithm. At that point in time, for some reason, I was using some preview release of Windows 8 and rather regrettably couldn’t use wget. But I coped by writing a short python script (rather than the more reasonable solution of rebooting into another operating system) which would incrementally clone the site’s database.
Because of rate limiting or something to that effect, the script only pulled about 10 questions every 40 seconds, and given that there were 30,000 questions in the database, the process wasn’t terribly fast. I eventually booted back into linux and rewrote the script so that it was resumable (for the event that the script might be interrupted for some reason on its scheduled week-long run).
However, by the next day, some number of them were downloaded and that small number was enough to train the classifier. The first thing was trying to run the classifier on the question set itself and comparing how well it fared. The results were actually surprisingly good, and after careful combing through the exceptions, it appeared that most of the errors manifested from the manual mislabeling of the original corpus.
After that initial successful result, I did a bit of work on a question extraction algorithm which would use the command line version of Abiword to convert .doc and .docx files that packets are usually distributed as into some machine readable format for feeding into the classifier. However, I never quite finished that, as school work caught up with me and I waited for the database to finish downloading.
Hiatus
On June 7th, about two weeks after I built the first promising prototype of the question parser, I had noticed that the background task had finished. Actually, it finished something like a week earlier, but I hadn’t noticed. Lurking around through Wikipedia, I discovered that Roger Craig, the famed Jeopardy! contestant who wrote a program to help study had actually attended my high school.
But nothing really happened after that. The school year was nearing a close and the after school clubs were having their last meetings of the year. There was the standardized testing and the anxiety about the imminent end of the year, and I had other projects which seemed more enticing at the time. Narrower in scope and more doable in shorter periods of time. This app was always on the radar, it just gradually slipped further and further back.
It’s Ac Attack
I wasn’t the only person in my school’s quiz bowl team who was interested in pursuing the idea. In fact, it was Ben who actually started the app first. I didn’t write code for the actual project until two weeks ago.
Early in July (or possibly late in June), Ben wanted to build that quiz bowl application when I was still working on a few other projects as well as an internship. I gave him the big JSON file of questions and he toiled away for the next few days, experimenting first with Ruby on Rails and then later settling with Node.JS (and the accompanying popular stacks).
Within a few days, he had put out a pretty impressive application using Mongoose, Jade, Twitter Bootstrap, Express, and Node running on Heroku at the (now defunct) its-ac-attack URL. Soon afterwards search was fairly functional and I started to take an interest in the project again (having almost finished another project, though at time of writing, I have yet to begin writing the blog post for that project).
I felt like exploiting this opportunity to get acquainted somewhat with popular NodeJS frameworks and tools. I haven’t done much with Node for over two years, and the landscape has changed considerably in the intervening years. It’s a fast growing and developing community. However, I never really found interest in building the entire app. Managing users and doing search has always struck me as somewhat boring, in part because it’s hardly untreaded territory.
I wanted to skip straight into the low latency websocket-driven synchronized multiplayer. Ben was still acclimating to the multimodal (if I’m using these buzzwords right) paradigm of writing code meant to be executed on both the client and the server, so I decided to prototype a multiplayer environment.
Prototype Quizbowl Application
Chronologically, this places us at about two weeks ago. That’s actually quite confusing because I wrote that sentence a bit over a month ago, where “a month ago” means August 8th, and “now” means September 12th. That is, you can imagine the gap between the first sentence in this paragraph and the sentence immediately succeeding it as joined by that scene from Monty Python where the animator dies of some fatal heart attack, in which case that animator is me, and I just sort of gave up on writing the readme.
And just like that, in the blink of a sentence, it’s been another month.
Question Set Management via Github
Folder Structure:
qb/
2013/
ACF Nationals/
Round 1
Round 2
Round 3
Round 4
Here’s what the JSON is like from Mongo
{ "__v" : 0, "_id" : { "$oid" : "506e3e938b3d831d6a000001" }, "answer" : "The {Bronze Horseman}: A Petersburg Tale [accept The Copper Horseman or Mednyy vsadnik: Peterburgskaya povest’]", "category" : "Literature", "difficulty" : "Open", "fixed" : 1, "inc_random" : 53.99425264270977, "num" : 1, "question" : "", "round" : "2011-ACFNationals-BrownFinal.doc", "seen" : 36, "tournament" : "ACF Nationals", "type" : "qb", "year" : 2011 }
The question thingy
tournament: ACF Nationals
year: 2011
---
difficulty: Open
num: 1
category: Literature
round: 2011-ACFNationals-BrownFinal.doc
answer: The {Bronze Horseman}: A Petersburg Tale [accept The Copper Horseman or Mednyy vsadnik: Peterburgskaya povest’]
In a footnote to this work, the author claims that Mickiewicz’s depiction of the same event as this work, while beautiful, was inaccurate. This poem opens with a man standing on the shore imagining a time when “all flags will visit us/ and we will celebrate in freedom,” after thinking that Nature intends for him to carve a window. This work contains a famous passage expressing the poet’s love for a city possessed of an “Admiralty needle,” and this poem’s protagonist is alleged to have the name he does because the poet is comfortable with it, a reference to that poet’s earlier work. The protagonist of this work sits on a marble sentry lion looking at his lover’s house instead of the title character behind him. After the death of his lover Parasha in a flood, this poem’s protagonist goes mad and wanders the streets before confronting the title figure. For ten points, identify this poem in which Yevgeniy imagines the title equestrian statue of Peter the Great chasing him through the streets of St. Petersburg, a poem by Alexander Pushkin.
---