CloudFall: A Text Editor 06 July 2012
This is probably a horrible time to think of writing an online text editor. The “market”, if you can call it that, is virtually saturated with worthy contenders and (figuratively) every day is marked by the entrance of some other text editor to the already crowded space. Part of the problem is that now, web based text editing components are actually pretty awesome. Ace and CodeMirror work really quite well and each have associated with them some very formidable integrated development environments, referring to Cloud9 and LightTable, respectively (albeit there are quite a few others, these seem to be probably the most funded). And at Google I/O 2012, they announced the new Chrome Packaged Apps, which expose new functionality (most relevant being the ability to open and save files from the local disk and operating offline by default), and their sample apps include no less than two text editors.
Nevertheless, I’ve always pined (probably an exaggeration) for the opportunity to indulge in something as meta as writing a text editor which I could use as a text editor for the text editor (which is, if you did not notice, that text editor). It’s probably the pinnacle of dogfooding (probably nice coming after a streak of making extensions that I never actually use). But this doesn’t really go anywhere in terms of explaining why I’m doing this rather than using someone else’s rather better developed text editor package. It really comes down to this chrome app which I was quite a fan of almost a year ago, called SourceKit. SourceKit is a text editor which runs in Chrome that synced with Dropbox. The version which was distributed on the Chrome Web Store never supported offline, which is sort of sad because that’s the one feature I really wanted. The other source of inspiration was Streamie, the real time node based twitter client which had an absolutely phenomenal scheme for contributing. You just needed to fork the repo on github and all your commits would be visible live on your own subdomain of the site.
Also, in the mean time, I had discovered this pretty awesome text editor (no, it’s not VI or Emacs, because I’m not nearly cool enough or dedicated enough to approach that steep precipice of a learning curve) called Sublime Text 2. I have a pretty good picture now of what exactly I want from a text editor based on that (actually, I don’t know if this is just some delusion which has manifested in my mind because I probably thought the same way about gedit and krita and komodo and aptana and notepad2 and notepad++ and dreamweaver before that).
The real drive to creating that text editor happened in the week before I was scheduled to attend Google I/O 2012. I knew I’d be in some situations lacking Internet, and I felt like writing words or code or something in that time. So in a few days I hacked together this text editor which had a vague resemblance to Sublime Text. It was based on Ace, like SourceKit before it, but obviously a newer version with a whole bunch of syntax and themes included. It used a modified version of the Dropbox component from SourceKit (it was changed moderately to accommodate Dropbox API 2.0 and to deal with binary things like array buffers and blobs). And I added a little heads-up-menu-esque file and command picker, quite reminiscent of Sublime Text (and to a lesser extent Ubuntu Unity).
And then I headed for the airplane having not actually used it much in practice hoping to be super productive while using it, which you could have probably been able to tell by the beginning of this sentence wouldn’t pan out. The first (quite major) flaw which I encountered was some bug which would end up wiping out any file that I tried to edit, and left me with a gaping chasm in my hard drive (this is a metaphor, because my Chromebook is solid state). I just hope nothing of value was lost, but it remains quite likely that it was the otherwise.
I had no real system for testing out changes to my own extension, and I was too paralyzed of the fear of deleting my own extension to try changing it. So the end result was that the entire duration passed with me hardly doing anything productive on the project, or using it for any productive means in itself. All that happened was my discovery that everyone is working on a text editor right now and I should probably quit right then and there and work on something perhaps more novel or productive. But I came back and fixed it and did some more on it, and I’m finally at the point at which I feel comfortable using it for some mostly useless things, like writing a blog post inside the project’s readme about the project itself.
Welcome to CloudFall. Yeah, I’m aware how dumb it sounds, but the fact that the new James Bond movie is going to be called Skyfall essentially demolishes any hope of using that name. But rather than using this as a vindication of how cool that name would be and abandoning it for some novel name, I’m just going to contrive something in a similar vain, hence the current working name. But rather than spending the first few lines complaining about the name of the product, I should probably lay down what exactly this project aims to be. It’s a text editor, not a terribly glamorous concept, I know, and this is especially not a terribly great time to start. This is hardly the first text editor, and certainly will not be the last (until this either never finishes or the world actually does end by the end of this year). It’s not the most full featured, but I guess it does need to have something which distinguishes it.
The main feature is largely inherited from SourceKit, which is the ability to sync with Dropbox. And instead of editing “live” off of Dropbox’s servers, it really is more of a sync. It’s built around Chrome’s FileSystem API, so it has its own sandboxed imaginary folder where it sticks all the files. Every time a file is loaded, it’s first downloaded onto its spot on the imaginary folder and subsequent edits get sent to both the local copy and the server. This architecture, in theory, means it probably won’t inadvertently overwrite, corrupt or delete your important data in the advent of some syncing issues. It keeps track of the latest synced revisions and tells Dropbox’s API that information so that it won’t try overwriting a newer version from elsewhere and It’ll somewhat gracefully save to a different file in such a circumstance (though that routine can hardly be declared well tested, so beware of complications). It should in that way retain very close to full functionality while offline, since just about everything it does is entirely offline (including the compilation of CoffeeScript and LESS, which is explained later on).
Built into the extension are a few of the tiny tweaks that I have installed on Sublime Text which I find fairly useful. For instance, the app includes a copy of the CoffeeScript and LESS compilers, and so whenever you are editing one of those types of files in the text editor, it’ll automatically compile and save it into the same directory whenever you hit the save key. That’s actually pretty useful because it gives CoffeeScript back that REPL (almost certainly a malapropism, but I’m not too familiar with developer work-cycle jargon, so please excuse that grievous offense) dynamic that JS developers are so familiar with. And to aid that sort of work, it can preview your files “live”, even offline. While it can’t open and edit binary files like pictures, it can still download and display them fine.
For writing walls of text which don’t really need syntax highlighting (I wonder if someone has a package on mainstream text editors that syntax highlights free form English grammar, sort of like giving people synesthesia for no real reason), it includes a word count widget. Also, because I feel like encouraging unhealthy behavior, right next to the word count is an indication of your current typing speed. I’m pretty sure someone could go into some moral discussion into why it’s a completely detrimental addition to create something which displays how quickly the author is typing because it encourages a mindset which doesn’t focus on creating the most concise or effective means of delivery for some message, but rather promotes meaningless verbosity. But sometimes I would imagine using this for school assignments and the ilk, and maybe it would be nice to know when I’m reaching my designated quota filling some unwritten word requirement. I’m not quite sure how reliable of a word count it gives, since the algorithm is primitive and by no means nuanced, but it should be able to give a sort of rough estimate of the number of words on a page.
I may have mentioned earlier that there are two primary systems for interacting with the application, both of which are keyboard shortcuts: Ctrl-O and Ctrl-P, meaning the file browser and the command palette, respectively. They both appear in the same sort of interface component and generally behave the same, but there are some slight differences in how they operate (obviously). There are actually two “browsing modes” for the file browser, where it shows files either from the local stored cache or online in Dropbox. That can be switched by selecting either “Browse Mode: Local Copy” or “Browse Mode: Remote Dropbox” from the command palette (though there should probably be some better interface logically placed on the file browser panel itself). Remote Dropbox only works when the user is online, so the default mode is the local one. The sole interface to this list of files is the filter search box on the bottom of that widget, where typing in stuff filters out things. Of the visible items, the cursor can be manipulated by using the arrow keys, and one of the options can be executed by hitting the enter key. The widget needs to be manually dismissed by hitting the Esc key (which allows you to semi-rapidly open several files or try different commands, like changing themes). When a folder is activated, the context then shifts to what is inside the folder, descending into the hierarchy. It’s possible to ascend by entering the directory “../“. To create a file or folder (Note that at time of writing, creating folders does not sync to Dropbox), just type “+yourfile.txt” (or if there are no search results, it’ll automatically select the option to create a file with that name). To delete a file, you likewise just prepend your command with a minus instead, for instance “-oldfile.txt”. It’s not nearly as counterintuitive or confusing as I presume this description is making it sound.
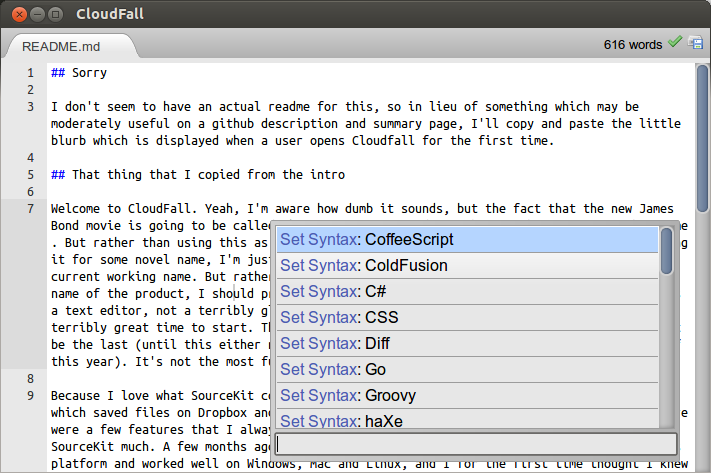
The command palette, given that the interface is basically the same has much in common with the file system, but it’s entirely flat and linear. It lacks the hierarchy that plagues the file system, and navigating it is considerably simpler. Since the list is filtered and updated live with every keystoke, it’s fairly easy to find whatever command you’re looking for. The filtering algorithm only searches for characters but disregards gaps, only paying attention to order. In other words, the query “seals”, may match “SEt SyntAx: coLdfuSion”, it also means that you can construct very short queries to find what you want.
At this point, I don’t think it’s a final project per se, there are still a few features are woefully dysfunctional like Find and Replace. But I think it fits my own use case, editing files on my Chromebook, even when offline. It’s fast and doesn’t take too many steps to start. But the interface isn’t exceedingly intuitive (Basically everything is accessed through two keyboard shortcuts). I haven’t found a witty logo for it (I just haven’t bothered looking), and at this point I’m just writing a blog post about it because I feel obligated to document whatever it is that I just did.
Maybe some day I’ll pick it up again, or if there’s some response at all to this blog post, and add those awesome collaboration features (which probably won’t be very useful because the entire thing is quite hackish and not particularly kind to the prospect of improvements). Maybe I’ll fix up the search and replace interface (read: get rid of whatever horrid mess exists and replace it with a new one from scratch). And maybe I might publish it in some form that is significantly less involved than cloning off github and packaging the app yourself.