August 2010 Archive
HTTP based federated protocol for real time hierarchical message manipulation 29 August 2010
In other words. It’s like google wave, but simpler in every possible way.
This protocol uses two servers. The federation server and the storage server. The latter is incredably simple. In fact, the reference implementation is only about 200 lines of JS (Node.JS FTW). Thats because a storage server accomplishes just about three things. It receives message deltas. It applies them. And it pushes the delta to all subscribers. The subscribers are the federation servers, they act on the behalf of multiple clients, keeping track of users, their inboxes, etc.
Anyway, the big part about the design is that there is only one unit of information, and that is the message. There’s no such thing as waves, wavelets, conversations, private replies, threads (sort of lying here), blips and other information. It’s just messages. Messages are stored on storage servers, and are filled with HTML and a tree of information.
Messages can have other messages inside them. It’s just some xml-ish stuff. <thread></thread> is a thread and <message name=”http://blahblahblah.com/blahblahblah"></message> is a message that goes inside the thread. You can stick it anywhere. In the middle (inline replies!) or at the end (normal replies!).
Messages don’t even have to have text. Gadgets are just messages that are slightly different.
http://github.com/antimatter15/awesomeness
There’s a lot that it doesn’t do because I’m too lazy to do it. And I can’t give you a live demo because I don’t have a node-enabled server.
HTML5/CSS3 Zooming User Interface 29 August 2010
I’m taking liberties with the concept of zooming user interfaces, but this is an example of something that lets you browse wikipedia by zooming in toward a link, and zooming out to go back. So I guess it’s more of a z-axis spatial visualization for history somewhat similar to what I guess Apple’s Time Machine program is like (though I have never tried it).
It uses html5’s popState and pushState to get the URL to change without reloading the page (which, btw people should use instead of the weird /#/ urls). It uses webkit transformations, which probably aren’t part of CSS3 since it’s vendor specific, but I haven’t had time to hack it to work on firefox, feel free to fork.
javascript:(function(){var scale=1,tx=innerWidth/2,ty=innerHeight/2,sx=innerWidth/2,sy=innerHeight/2;document.onmousewheel=function(a){if(a.wheelDelta){if(a.wheelDelta>0)scale*=a.wheelDelta/1000;if(a.wheelDelta<0)scale/=-a.wheelDelta/1000}scale<0.05&&history.go(-1);showTransform();a.preventDefault()};window.onpopstate=function(a){loadPage(a.state.url)}; function showTransform(){document.body.style.webkitTransform="scale("+scale+") translate("+(innerWidth/2-tx)+"px,"+(innerHeight/2-ty)+"px)";var a=document.elementFromPoint(innerWidth/2,innerHeight/2);if(a.nodeName=="A"&&a.offsetWidth*scale>0.3*innerWidth&&a.offsetHeight*scale>0.3*innerHeight){console.log("clicky");loadPage(a.href);history.pushState({url:a.href},a.href,a.href)}} function loadPage(a){var b=new XMLHttpRequest;b.open("get",a,true);b.onload=function(){document.body.innerHTML=b.responseText;showTransform()};b.send(null);scale=1;tx=innerWidth/2;ty=innerHeight/2;sx=innerWidth/2;sy=innerHeight/2;showTransform()}var dragging=false;document.onmousemove=function(a){if(dragging){tx+=(sx-a.pageX)/scale;ty+=(sy-a.pageY)/scale;sx=a.pageX;sy=a.pageY;showTransform();a.preventDefault();a.stopPropagation()}}; document.onmousedown=function(a){dragging=true;sx=a.pageX;sy=a.pageY;a.preventDefault()};document.onclick=function(a){a.preventDefault()};document.onmouseup=function(a){dragging=false;a.preventDefault()};})()
So that’s a bookmarklet. feel free to click it on this site and it’ll get rid of the infinite scrolling and for some reason it doesn’t work well on this site. Try it on wikipedia.
(function(){
var scale=1,
tx=innerWidth/2,
ty=innerHeight/2,
sx=innerWidth/2,
sy=innerHeight/2,
mx=innerWidth/2,
my=innerHeight/2,
document.onmousewheel=function(a){
console.log(a.wheelDelta, scale)
scale = Math.exp(Math.log(scale) + a.wheelDelta / 200)
if(scale<0.05) history.go(-1);
showTransform();
a.preventDefault()
};
window.onpopstate=function(a){
loadPage(a.state.url)
};
function showTransform(){
document.body.style.webkitTransform="scale("+scale+") translate("+(mx-tx)+"px,"+(my-ty)+"px)";
var a=document.elementFromPoint(innerWidth/2,innerHeight/2);
if(a.nodeName=="A"&&a.offsetWidth*scale>0.3*innerWidth&&a.offsetHeight*scale>0.3*innerHeight){
console.log("clicky");
loadPage(a.href);
history.pushState({url:a.href},a.href,a.href)
}
}
function loadPage(a){
var b=new XMLHttpRequest;
b.open("get",a,true);
b.onload=function(){
document.body.innerHTML=b.responseText;
showTransform()
};
b.send(null);
scale=1;
tx=innerWidth/2;
ty=innerHeight/2;
sx=innerWidth/2;
sy=innerHeight/2;
showTransform()
}
var dragging=false;
document.onmousemove=function(a){
if(dragging){
tx+=(sx-a.pageX)/scale;
ty+=(sy-a.pageY)/scale;
sx=a.pageX;
sy=a.pageY;
showTransform();
a.preventDefault();
a.stopPropagation()
}
};
document.onmousedown=function(a){
dragging=true;
sx=a.pageX;
sy=a.pageY;
a.preventDefault()
};
document.onclick=function(a){
a.preventDefault()
};
document.onmouseup=function(a){
dragging=false;
a.preventDefault()
};
})()
BitTorrent in JavaScript with Node 29 August 2010
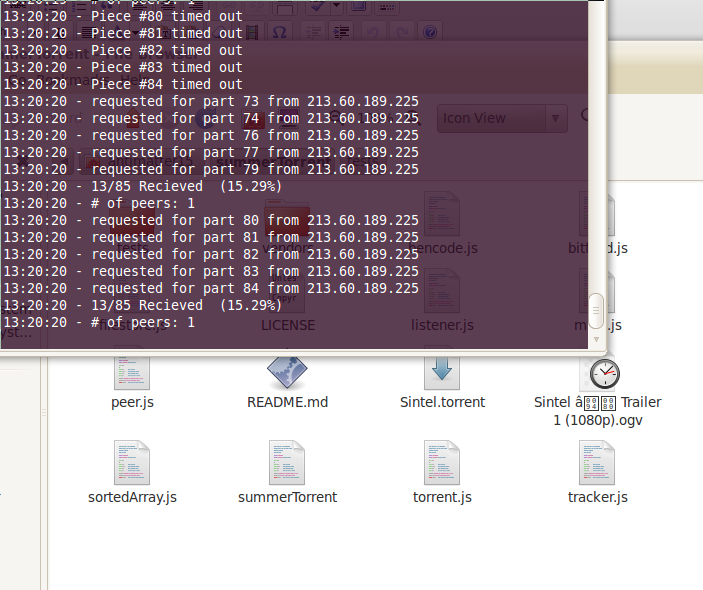
A few months ago I tried to make a bittorrent client in javascript. But a few days after it started, I found out that there were already other projects with the same goal. The most complete of them was summerTorrent. However, though (I thought) it was so insanely close, it wasn’t finished. So anyway, I made a few changes that at least made basic torrenting functionality working.
Chrome Extension Desktop Search 29 August 2010
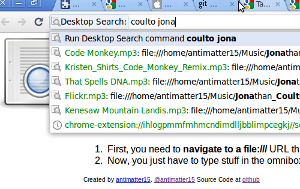

I felt like making some chrome extensions recently. so this is a almost totally useless one, since it uses the experimental APIs. Basically, since the new versions of chrome let you have content scripts that act off file:/// urls, you can make a script that indexes the local files and store it to a searchable index, as I have done. Plus, there’s a new omnibox api, so you can use that to search too.
Probably won’t work for anyone. but anyway, feel free to fork it on github.
Chrome Extension Hide Element 29 August 2010

https://chrome.google.com/extensions/detail/omjoegfimgdcgigodfpnjefanhfiagae
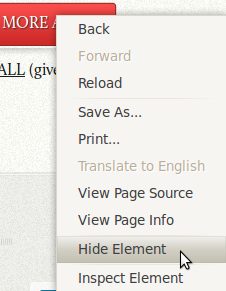
It’s a simple extension that uses the new chrome context menu API to gain DOM access to hide an element. It’s actually a lot more complicated than it should be since, probably chrome’s multi-process architecture makes it impossible to actually pass the DOM over, so instead you have to create a content script that listens and logs all click events and when a context menu action is triggered, you send a message to the content script which applies an action to the selected DOM node.
Anyway. Code here. http://github.com/antimatter15/hideelements
microwave on app store 23 August 2010
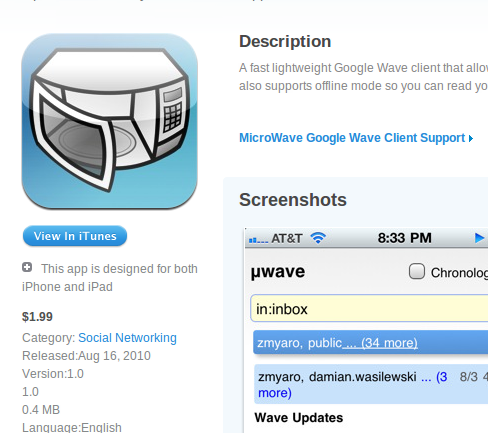
http://itunes.apple.com/us/app/microwave-google-wave-client/id386081118?mt=8
So microwave is now on the app store. Though wave was just announced to be shut down, I had the app done already (though I was waiting for a wave server update so thread continuation and attachment uploading would work), and I just published it anyway. So here it is. Grab it while wave still works :). It supports offline, so you can cache some waves and read them on-the-go.
Deep Integration Wave API Sample Blogger 06 August 2010
http://w2embedtest.blogspot.com/2010/08/intense.html
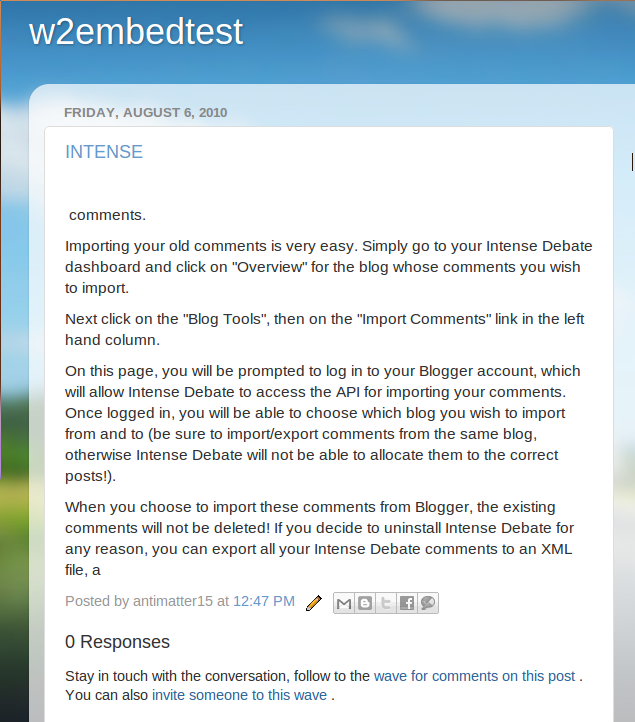
It’s not just one post, it’s the whole blog! http://w2embedtest.blogspot.com/
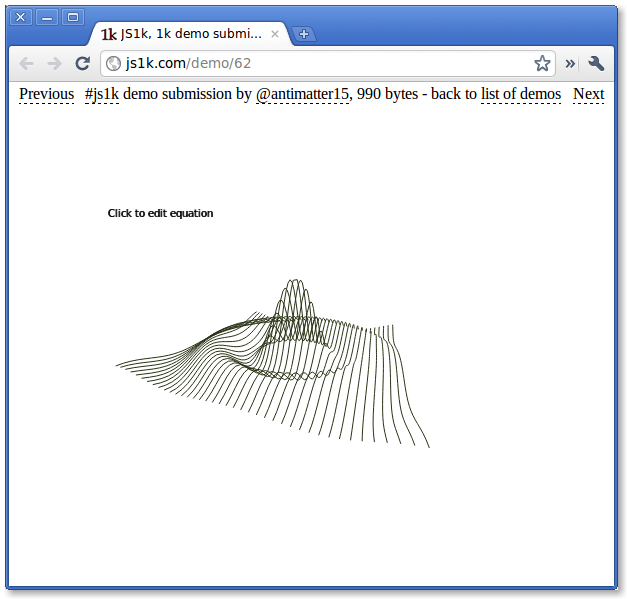
1k JS 3d Function Plotter 06 August 2010
 Screenshot-JS1k, 1k demo submission [62] - Chromium-1
Screenshot-JS1k, 1k demo submission [62] - Chromium-1
Interestingly, it does seem that a lot of the demos for the js1k competition are a whole lot more impressive than the 10k competition. Despite that js1k started with no prizes and 10k has a collective $10,000 worth of prizes. Though I do have several entries on both. Anyway, this is the continuation of my old 3d function plotter, but that one doesn’t work anymore because i’m evil and hotlinked the github repo and three.js updated in an api-breaking way.
Anyway, after you vote up http://10k.aneventapart.com/Entry/46 and http://10k.aneventapart.com/Entry/18 you should totally try out my 3d function plotter at http://js1k.com/demo/62
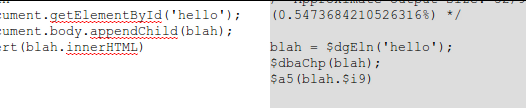
DOM Indexer JS Compression 05 August 2010
There’s lots of compression systems for JS out there. There’s the really smart JS rewriter magical rhino-based ones like Closure and YUI. There’s the string-based ones, packer base62, huffman, and lz77. But of the latter category, they all rely on a sort of dictionary coder, where the dictionary (or huffman tree) needs to be sent alongside the compressed content.
Unlike strings of bits, javascript code often refers to methods on the document object model. If we were to crawl the DOM, we could get a list of DOM properties and use that as the shared dictionary which doesn’t need to be changed, sent or stored. Ever.
Example:
document.getElementById —> $dgEln
document.body.appendChild(s); -> $dbaChp(s);
And as the dictionary never needs to be stored, it’s dynamically computed based on the default browser DOM, there is a constant overhead for the indexer. The dictionary does not change size based on the size of the content.
The first prototype relied on recursively indexing properties 2-3 levels from window using the ES5 Object.getOwnPropertyNames. That feature is only supported on IE9, Chrome 6, probably the latest versions of Safari and Firefox 4. As such, it severely limits the applicability of the algorithm.
Version two switches it to a simple for..in loop. The problem here is that it’s no loner possible to index certain things. Properties like Math, which are marked DontEnum internally can not be iterated, and thus can not be compressed (Math.cos would have been $Mac8). However, it probably makes up for this by recursively indexing things substrings of the discovered objects. So document.getElementById would be interpreted as the full document.getElementById instead of seperately compressing document and getElementById. It also uses a new hash function which makes the output more readable and the length proportional to the length of the source. length becomes $l6, and document.body.removeChild becomes $dbrChp. However, this also removes the possibility of that nice fallback on things not supported by the browser. (if(document.getElementsByClassName){}else{} would have been translated as d3k2.s93k and back as document.s93k on browsers that dont support it and so browser detection gracefully degrades without blah is not defined errors).
Overall. What is the compression ratio? Not that great. If you do lots and lots of DOM access then you might get a decent ratio, but the code is slow and the ratios are relatively insignificant.
Minify: http://antimatter15.com/misc/js-minify/minify.html
Maxify (decoder): http://antimatter15.com/misc/js-minify/maxify.html
jailbreakme.com 01 August 2010
I couldn’t resist looking into the source of it. It is obfuscated a bit, but there are some interesting parts. Example: How it detects device models.
For iPad, well there’s just one iPad so they just search the UA string for iPad and it’s totally iPad1,1. iPhone 4 is detected by the global devicePixelRatio property, because the pixel is dying. Differentiating between iPhone models (not just firmware versions) is pretty awesome. They do a speed test. Specifically, SunSpider. It’s pretty much the de-facto standard web benchmark nowadays, and it was also started by Apple for the Webkit project.
Apart from that, the exploit itself is PDF based. Which is interesting as Adobe Reader accounted for 80% of exploits in 2009. However, iOS’s implementation is probably totally independent, but it’s neat seeing this happen. The exploit is located at http://jailbreakme.com/_/device_model/device_firmware.pdf. For example, the iPhone 4’s URL would be http://jailbreakme.com/_/iPhone3,1/4.0.pdf. The resulting file is 12.9KB. I assume it’s some pretty standard attack code because I’m not a hacker and I know absolutely nothing about that.