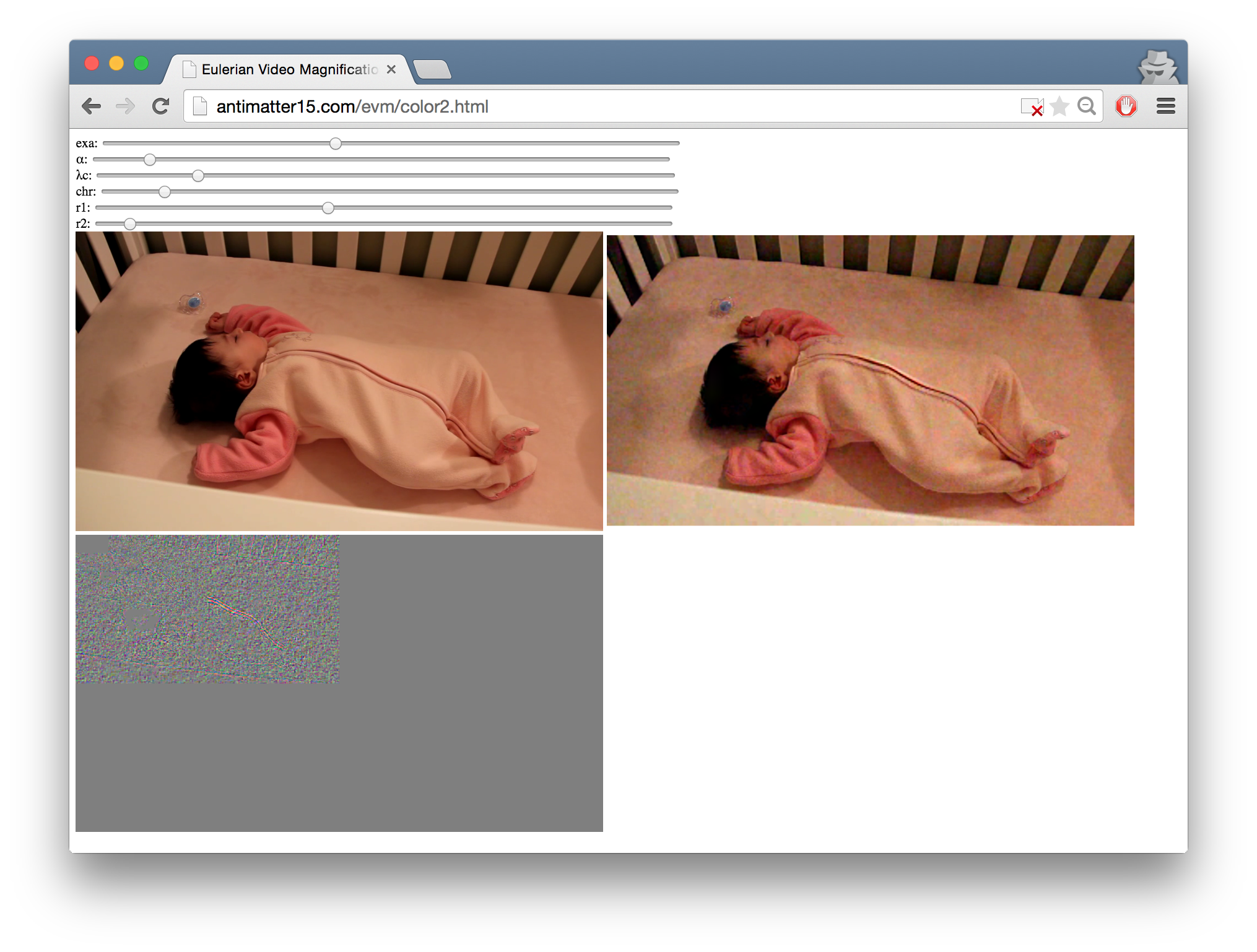
For our final project, we had to reproduce some computer vision algorithm from a list. One of them was Eulerian Video Magnification, that cool demo which has made its rounds on Hacker News on several occasions.
I’m almost certainly an outsider, so I can’t speak for the gaming or VR communities, but to me the Facebook acquisition (and the Abrash onboarding announcement) signals that the new Oculus is more interested in bringing to fruition the Metaverse from Snow Crash, and that the hardware (Rift DK1, Crystal Cove, DK2, etc.) has been reduced to a mere means to attaining that end.
I think the “original” product was always contextualized as a gaming accessory, as the vested (financial, by virtue of Kickstarter) interest was held by gamers hoping to utilize this new form factor and experience.
I guess the question is what exactly is Oculus? In the beginning, I’d venture that the answer was simple. They were building a head mounted display which would be affordable, leveraging the technological improvements of the past decade (cheap high quality displays meant for phones and tablets, faster graphics cards). The hardware was their concern, and the software, the games and experiences, everyone else’s.
From the QuakeCon Abrash-Carmack-Luckey panel (which may be a bit dated), Carmack admits that he isn’t really interested in developing the hardware, as opposed to Luckey whose passion really lies in developing that hardware. Carmack, Abrash, and ultimately Facebook are alike in that they are software titans, which I think really shifts the balance in terms of the intentions for Oculus.
Sure there’s the hardware aspect, which is far from a solved problem. But given the palpable progress of Crystal Cove and the famed Valve prototypes, the end is nigh (to be less melodramatic, the consumer edition is on the brink of happening). But if you look at the teardowns, it’s a tablet screen, LEEP optics, an inertial measurement unit, and infrared tracker. The underlying display technology isn’t going to get better, because it’s already piggybacking off a much larger market where even Facebook’s considerable budget is a drop in the bucket.
I think since Carmack joined Luckey’s shop, the destiny of Oculus has shifted from producers of a mere display commodity to a more vertically integrated entity which develops both the hardware and the software which drives its progress and adoption (a la Apple).
And that accumulation of software talent is, I think, itself, a credible threat to the game developers hoping to build games for the Rift- because it establishes a first party, and that has the risk of pushing third party developers into the realm of the second class citizen.
But this dynamic of conflicted interest has played out several times before, and it is not usually an existential risk to the third parties. With transitions flipped, Microsoft had to deal with the risk of alienating OEMs when it started developing its own hardware- the Surface tablet. Likewise, Google’s decision to develop Nexus tablets and phones (and the acquisition of Motorola Mobility) was criticized because it would inevitably result in favoritism for its own devices, weakening relationships between LG, HTC, Samsung and the ilk.
The risk in stifling competition is inherent in any kind of move involving integration (horizontal, vertical, or 37 degrees counterclockwise), but on the other hand, this dissolution of the separation of interests enables the unimpeded progress toward a coherent vision.
And I think that coherent vision is to construct Virtual Reality that is truly grand, world-encompassing and liable to all the philosophical depth missing from prior incarnations outside of science fiction. Not the kind of gimmicky interactions retrofitted into first person shooters, jumping onto the bandwagon represented by that euphemistic initialism “VR”.
I don’t think post-acquisition institutional independence or agency ultimately matter, because the seeds for something larger has already been sown.
Is this new Oculus a threat to existing companies and their efforts to build VR games? Perhaps, this has to be true on some level, the more interesting question, I think, is whether or not this cost will be offset (and then some) by those inspired by Oculus’s vision and audacity and that which can be built on this new and boundless meta-platform.
..so I just finished writing all of this. I originally meant it as a Hacker News comment, and then halfway through I decided not to ultimately submit it, because if you really think about it, this is all kind of silly. I feel like one of those poor conspiracy theorists connecting dots where the lines may not exist. I’m sure there are nontrivial technical challenges that still need to be vanquished, but as an outside observer, I’d claim that Dunning-Kruger permeates my perception, and I can’t possibly gauge the extent of problems that remain (the less you know, the simpler it all seems). And I have a habit of conflating long term with short term (when I was 12, I vowed not to learn to drive, because surely, aeons from then, when I turned 16, the cars would no doubt drive themselves). I mean, I wrote all of this like five minutes ago, it can’t be _that _wrong already, right?
As with any minor stepping stone on the road to hell relentless trajectory of Atwood’s Law, I probably don’t need to justify the existence of yet another “x, but now in Javascript!”, but I might as well try. After all, we all would like to think that there’s some ulterior motive to fulfilling that prophesy.
On tablet or other touchscreen devices- of which there are quite a number of nowadays (as the New Year’s Eve post, I am obliged to include conjecture about the technological zeitgeist), a library such as Ocrad.js might be used to add handwriting input in a device and operating system agnostic manner. Oftentimes, capturing the strokes and sending them over to a server to process might entail unacceptably high latency. Maybe you’re working on an offline-capable note-taking app, or a browser extension which indexes all the doge memes that you stumble upon while prowling the dark corners of the internet.
If you’ve been following my trail of blog posts recently, you’d probably be able to tell that I’ve been scrambling to finish the program that I prototyped many months ago overnight at a Hackathon. The idea of the extension was kind of simple and also kind of magical: a browser extension that allowed users to highlight, copy, and paste text from any image as if it were plain text. Of course the implementation is a bit difficult and actually relies on the advent of a number of newfangled technologies.
If you try to search for some open source text recognition engine, the first thing that comes up is Tesseract. That isn’t a mistake, because it turns out that the competition is worlds away in terms of accuracy. It’s actually pretty sad that the state of the art hasn’t progressed substantially since the mid-nineties.
A month ago, I tried compiling Tesseract using Emscripten. Perhaps it was a bad thing to try first, but soon I learned that even if it did work out, it probably wouldn’t have been practical anyway. I had figured that all OCR engines had been powered by artificial neural networks, support vector machines, k-nearest-neighbors and their machine learning kin. It turns out that this is hardly the norm except in the realm of the actually-accurate, whose open source provinces live under the protection of Lord Tesseract.
GOCR and Ocrad are essentially the only other open source OCR engines (there’s technically also Cuneiform, but the source code is in a really really big zip file from some website in Russian and its also really slow according to benchmarks). And something I didn’t realize until I had peered into the source code is that they are powered by (presumably) painstakingly written rules for each and every detectable glyph and variation. This kind of blew my mind.
Anyway, I tried to compile GOCR first and was immediately struck by how easy and painless it had been. I was on a roll, and decided to do Ocrad as well. It wasn’t particularly hard- sure it was slightly more involved but still hardly anything.
GOCR and Ocrad both only operate on NetPBM files (supporting other files is done in typical unix fashion by piping the outputs from programs that convert file formats). Nobody really uses NetPBM anymore, so in order to handle a typical use case, I’d need some means of converting from raw pixel values into the format. I Googled around for Javascript implementations of PBM/PGM/PNM, finding nothing. I opened the Wikipedia page on the format and was pleased to found out why: the format is dirt simple.
If you know me in person, you’ll probably know that I’m not a terribly decisive person. Oftentimes, I’ll delay the decision until there isn’t a choice left for me to make. Anyway, serially-indecisive-me strikes again, so I alternated between the development of GOCR.js and Ocrad.js, leading up to a simultaneous release.
But in the back of my mind, I knew that eventually I would have to pick one for building my image highlighting project. I had been leaning toward Ocrad the whole time because it seemed to be a bit faster and more accurate when it came to handwriting.
Anyway, I spent a while building the demo page. It’s pretty simple but I wouldn’t describe it as ugly. There’s a canvas in the center which can be drawn to in arbitrary fonts pulled via the Google Font API. There’s a neat little thing which lets you draw things on the canvas. And to round out the experience, you can run the OCR engine on your own images, by loading the image file onto canvas to support any file the browser does (JPG, GIF, BMP, WebP, PNG, SVG) or by directly feeding the engine in its native NetPBM formats.
What consistently amazes me about Optical Character Recognition isn’t its astonishing quality or lack thereof. Rather, it’s how utterly unpredictable the results can be. Sometimes there’ll be some barely legible block of text that comes through absolutely pristine, and some other time there will be a perfectly clean input which outputs complete garbage. Maybe this is a testament to the sheer difficulty of computer vision or the incredible and under-appreciated abilities of the human visual cortex.
At one point, I was talking to someone and I distinctly remembered (I know, all the best stories start this way) a sense of surprise when the person indicated that he had heard of Tesseract, the open source OCR engine. I had appraised it as somewhat more obscure than it evidently was. Some time later, I confided about the incident with a friend, and he said something along the lines of “OCR is one of those fields that everyone comes across once”.
I guess I’ve kind of held onto that thought for a while now, and it certainly seems to have at least a grain of truth. Text embedded into the physical world is more or less our primary means we have for communication and expression. Technology is about building tools that augment human capacity and inevitably entails supplanting some human capability. Data input is a huge bottleneck, and while we’re kind of sidestepping the problem with things like QR codes by bringing the digital world into the physical. OCR is just one of those fundamental enabling technologies which ought to be as broad in scope as the set of humans who have interacted with a keyboard.
I can’t help but feel that the rather large set of people who have interacted with the problem character recognition have surveyed the available tools and reached the same conclusion as your miniature Magic 8 Ball desk ornament: “Try again later”. It doesn’t take long for one to discover an instance of perfectly crisp and legible type which results in line noise of such entropy that it’d give DUAL_EC_DRBG a run for its money. “No, there really isn’t any way for this to be the state of the art.” “Well, I guess if it is, then maybe it’ll improve in a few years- technology improves quickly, right?”
You would think that some analogue of Linus’s Law would hold true: “given enough eyeballs, all bugs are shallow”- especially if you’re dealing with literal eyeballs reading letters. But incidentally, the engine that absolutely everyone uses was developed three decades ago (It’s older than I am!), abandoned for a decade before being acquired and released to the world (by our favorite benevolent overlords, Google).
In fact, what’s absolutely stunning is the sheer universality of Tesseract. Just about everything which claims to have text recognition as a feature is backed by it. At one point, I was hoping that Mathematica had some clever routine using morphology and symbolic new kinds of sciences and evolved automata pattern recognition. Nope! Nestled deep within the gigabytes of code lies the Chuck Testa of textadermies: Tesseract.
At time of writing, a video is being processed by my v2.py script, it’s only eight lines of code thanks to the beautifully terse nature of python and SimpleCV. And since it’s clearly not operating at the breakneck speed of one frame per second, I don’t have time to write this README, meaning that I’m writing this README. But since I haven’t actually put a description of this project out in writing before, I think it’s important to start off with an introduction.
It’s been over a year since I first wrote code for this project. It really dates back to late April 2011. Certainly it wouldn’t have been possible to write the processor in eight painless lines of python back then, when SimpleCV was considerably in more of an infancy. I’m pretty sure that puts the pre-production stage of this project in about the range of a usual Hollywood movie production. However, that’s really quite unusual for me because I don’t tend to wait to get started on projects often. Or at least, I usually publish something in a somewhat workable state before abandoning it for a year.
However, the fact is that this project has been dormant for more than an entire year. Not necessarily because I lost interest in it, but because it always seemed like a problem harder than I had been comfortable tackling at any given moment. There’s a sort of paradox that afflicts me, and probably other students (documented by that awesome Calvin and Hobbes comic) where at some point, you find a problem hard enough that it gets perpetually delayed until, of course, the deadline comes up and you end up rushing to finish it in some manner that only poses a vague semblance to the intent.
The basic premise is somewhat simple: videos aren’t usually the answer. That’s not to say video isn’t awesome, because it certainly is. YouTube, Vimeo and others provide an absolutely brilliant service, but those platforms are used for things that they aren’t particularly well suited for. Video hosting services have to be so absurdly general because there is this need to encompass every single use case in a content-neutral manner.
One particular example is with music, which often gets thrown on YouTube in the absence of somewhere else to stick it. A video hosting site is pretty inadequate, in part because it tries to optimize the wrong kinds of interactions. Having a big player window is useless, having an auto-hiding progress slider and having mediocre playback, playlist and looping interfaces are signs that a certain interface is being used for the wrong kind of content. Contrast this to a service like SoundCloud which is entirely devoted to the interacting with music.
The purpose of this project is somewhat similar. It’s to experiment with creating an interface for video lectures that goes above, in terms of interactivity and in terms of usability (perhaps even accessibility), what a simple video can do.
So yeah, that’s the concept that I came up with a year ago. I’m pretty sure it sounds like a pretty nice premise, but really at this point the old adage of “execution is everything” starts to come into play. How exactly is this going to be better than video?
One thing that’s constantly annoyed me about anything video-related is the little progress slider tracker thing. Even for a short video, I always end up on the wrong spot. YouTube has the little coverflow-esque window which gives little snapshots to help, and Apple has their drag down to do precision adjustment, but in the end the experience is far from optimal. This is especially unsuitable because moreso in lectures than perhaps in any other type of content, you really want to be able to step back and go over some little thing again. Having to risk cognitive derailment just to go over something you don’t quite get can’t possibly be good (actually, for long videos in general, it would be a good idea to snap the slider to the nearest camera/scene change which wouldn’t be hard to find with basic computer vision, since that’s in general, where I want to go). But for this specific application, the canvas itself makes perhaps the greatest navigatory tool of all. The format is just a perpetually amended canvas with redactions rare, and the most sensible way to navigate is by literally clicking on the region that needs explanation.
But having a linear representation of time is useful for pacing, and to keep track of things when there isn’t always a clear relationship between the position of the pen and time. A more useful system would have to be something more than just a solid gradient bar crawling across the bottom edge of the screen, because it would also convey where in the content the current step belongs. This is something analogous to the way YouTube shows a strip of snapshots when thumbing through the slider bar, but in a video-lecture setting we have the ability to automatically and intelligently build populate the strip with with specific and useful information.
From this foundation we can imagine looking at the entire lecture in it’s final end state, except with the handwriting grayed out. The user can simply circle or brush over the regions which might seem less trivial, and the interface could automatically stitch together a customized lecture at just the right pacing, playing back the work correlated with audio annotations. On top of that, the user can interact with the lecture by contributing his or her own annotations or commentary, so that learning isn’t confined to the course syllabus.
Now, this project, or at least its goals evolved from an idea to vectorize Khan Academy. None of these truly requires a vector input source, in fact many of the ideas would be more useful implemented with raster processing and filters, by virtue of having some possibility of broader application. I think it may actually be easier to do it with the raster method, but I think, if this is possible at all, it’d be cooler to do it using a vector medium. Even if having a vector source was a prerequisite, it’d probably be easier to patch up a little scratchpad-esque app to record mouse coordinates and to re-create lectures rather than fiddling with SimpleCV in order to form some semblance of a faithful reproduction of the source.
I’ve had quite a bit to do in the past few months, and that’s been reflected in the kind of work I’m doing. I guess there’s a sort of prioritization of projects which is going on now, and this is one of those which has perennially sat on the top of the list, unperturbed. I’ve been busy, and that’s led to this wretched mentality to avoid anything that would take large amounts of time, and I’ve been squandering my time on small and largely trivial problems (pun not intended).
At this point, the processing is almost done, I’d say about 90%, so I don’t have much time to say anything else. I really want this to work out, but of course, it might not. Whatever happens, It’s going to be something.