Recovering Deleted Data from LevelDB 02 December 2015
It was 4am this morning, and I did something stupid. I was trying to write something which would automatically delete all empty documents. Within a few seconds of running it, all my precious data was gone. Oops.
There’s probably some grander lesson to be learned about keeping routine backups and not being an idiot. But the strength of that parable is somewhat weakened because I did manage to get the data back.
How LevelDB Works
LevelDB, developed by Sanjay Ghemawat and Jeff Dean of Google, is a fast key-value store based on a log-structured merge tree.
It’s not a relational database. It can’t do complex SQL queries. In fact, the only type of query that one can do is to ask for the set of entries whose keys fit lexicographically in some range. Think of it as a list of entities perpetually sorted by a key, where you can quickly read out any entry (or contiguous range) with a simple binary search.
It’s not just a metaphor— the basic primitive underlying LevelDB is literally called an SSTable (Sorted String Table). If you have a big arbitrarily large sorted list, the task of locating any single entity in a sorted list can be done in O(log n) time, which is nice because hopping around the big spinning metal hard disk platter is glacially slow in computer time.
In RAM, hopping around is pretty fast. It’s part of the name— Random Access Memory. In RAM you can maintain a balanced binary search tree, so that you can search, insert, delete, or update the contents of any entry in O(log n) time— all while keeping the contents sorted.
Computers tend to have a limited amount of RAM compared to hard disk space, so most databases have to somehow deal with both beasts. To a certain extent, LevelDB plays to the strengths of each while using the other to fill in weaknesses.
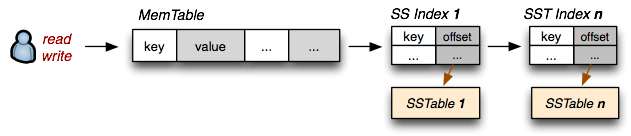
To add some entry to the key-value store, LevelDB first sticks it into RAM— in particular some sort of data structure that keeps everything all nice and sorted. But over time, this chunk of memory may grow uncomfortably large, at which point its sorted contents get flushed into a file, and the old chunk of memory is emptied and ready for new data.
Once data is saved to the disk, the saved SSTables are essentially treated as immutable. Otherwise, if you want to keep the data sorted you might have to rewrite the entire file whenever a new entry is added, or an old one is deleted. This immutability property is really what ends up saving me, because it means that in spite of deleting everything— nothing is ever truly lost.
To look up some range of entries, LevelDB first checks RAM in case something matching the query has been manipulated recently. Then it checks the little immutable chunks which have already been flushed to disk, and merges them all together quickly in a manner similar to merge sort.
There’s some more to it which I haven’t covered, such as an append-only log to aid recovery in the event of some catastrophic power failure or software crash, and the process by which older SSTables get compacted together. But this essentially represents the basic design of an LSM database, at least enough to understand the principle of recovering deleted files.
LevelDB Structure
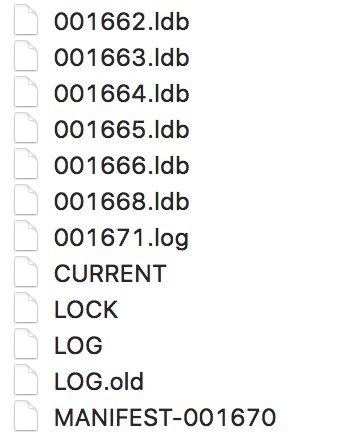
When you save some stuff to a LevelDB database, what you find is actually a directory consisting of a couple of .log files, .ldb files, MANIFEST, CURRENT, LOG and LOCK. As far as I’m aware the log files are temporary and kept in case the database is interrupted before it has an opportunity to write things down into a sorted table. Thus I’ll pretend that after having cleanly exited the database (following accidentally deleting lots of stuff), all the content which might possibly be interesting is within the .ldb files.
If you try to open up an .ldb in a hex editor, you’ll notice bits which look tantalizingly like the data you might want to recover, albeit subtly mangled by the Snappy compression algorithm.
Recovery
While you might imagine that being able to access previous versions of the data would be a natural and obvious affordance for a log-structured immutable append-only key-value store, I couldn’t find any APIs for accessing deleted data.
A good first step might be figuring out some way to parse those .ldb files. Fortunately, it’s well-documented enough that there are actually third-party implementations. And from the looks of it’s actually pretty simple.
That golang leveldb repo is particularly cool because it includes a helper tool ldbdump which reads in an .ldb file and dumps its contents. In fact the whole process of using it was surprisingly rather painless. I just ran go get github.com/golang/leveldb, navigated to the cmd/ldbdump directory and ran go build -o ldbdump main.go. I then wrote a little Python script which would call that program for all the .ldb files in a particular directory and parse it into a more canonical JSON form.
base = "test-stuff copy"
import os
from subprocess import Popen, PIPE
import json
import ast
for f in os.listdir(base):
if f.endswith(".ldb"):
process = Popen(["ldbdump", os.path.join(base, f)], stdout=PIPE)
(output, err) = process.communicate()
exit_code = process.wait()
for line in (output.split("\n")[1:]):
if line.strip() == "": continue
parsed = ast.literal_eval("{" + line + "}")
key = parsed.keys()[0]
print json.dumps({ "key": key.encode('string-escape'), "value": parsed[key] })
Out of this I got a 73MB JSON file, which seemed to have all the contents in some form but unfortunately ordered by the key. This is bad because it conflates different versions of a particular key— an object may have been changed, deleted, and created again.
{"value": "{\"id\":\"Whole Earth Catalog\",\"type\":\"text\",\"parent\":\"__root__\",\"created\":1447821578094,\"list\":[\"MI11NZ\"]}", "key": "!entities/aleph!Whole Earth Catalog\\x01RI\\x05\\x00\\x00\\x00\\x00"}
{"value": "{\"id\":\"Wikia\",\"type\":\"text\",\"parent\":\"__root__\",\"created\":1447821578094,\"list\":[\"XB8UAU\"]}", "key": "!entities/aleph!Wikia\\x01UI\\x05\\x00\\x00\\x00\\x00"}
{"value": "{\"id\":\"Will Ferrell\",\"type\":\"text\",\"parent\":\"__root__\",\"created\":1447841260204,\"list\":[\"AKVVBF\"]}", "key": "!entities/aleph!Will Ferrell\\x01=N\\x05\\x00\\x00\\x00\\x00"}
One curious thing I noticed was the presence of some strange binary digits after the end of each key. After a little bit of experimentation it turns out that if you convert that binary string into a number, and sort the entire database by it, sticks all the changes in the proper chronological order!
import sys
import json
import ast
import binascii
things = []
for line in sys.stdin:
obj = json.loads(line)
halves = obj['key'].split("\\x", 1)
key = ast.literal_eval("'\\x" + halves[1].replace("\\\\u00", "\\x") + "'")
if len(key) == 8:
time = int(binascii.hexlify(key[1:][::-1]), 16)
things.append((time, halves[0], obj['value']))
for x in sorted(things, key = lambda k: k[0]):
print json.dumps(x)
And my precious data is now saved! Or well, rather, it always was— but now I finally have access to it in some reasonable form.
I could see the first few entries, which happened to be some particularly fecal test data
[1, "!changes/wumbo/!00000001448849217216", "poop"]
[2, "!entities/wumbo/!00000001448849471307", "poop"]
[3, "!changes/wumbo/!00000001448849471308", "poop"]
Then some data in the middle with an imported movie database
[2435, "!changes/merp!000000014488557172160000001163", "Deja Vu"]
[2437, "!changes/merp!000000014488557172160000001164", "Gattaca"]
[2439, "!changes/merp!000000014488557172170000001165", "Sunshine"]
And of course, the part of it where I accidentally deleted everything
[394061, "!entities/aleph!OYHEDW", ""]
[394062, "!entities/aleph!Gerry Sussman", ""]
[394063, "!entities/aleph!VSPKP8", ""]
So I guess that’s it! In case you ever get stuck in a rut where you’ve unwittingly deleted the contents of your LevelDB and forgot to keep decent backups, and you’re lucky enough that the changes haven’t been compactified yet, you can possibly get your data back.
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 57 FB 80 8B 24 75 47 DB